Experiments
We benchmark the state-of-the-art methods on zero-shot panoptic segmentation (ZSP), zero-shot semantic segmentaion (ZSS), zero-shot instance segmentation (ZSI), and zero-shot detection (ZSD).
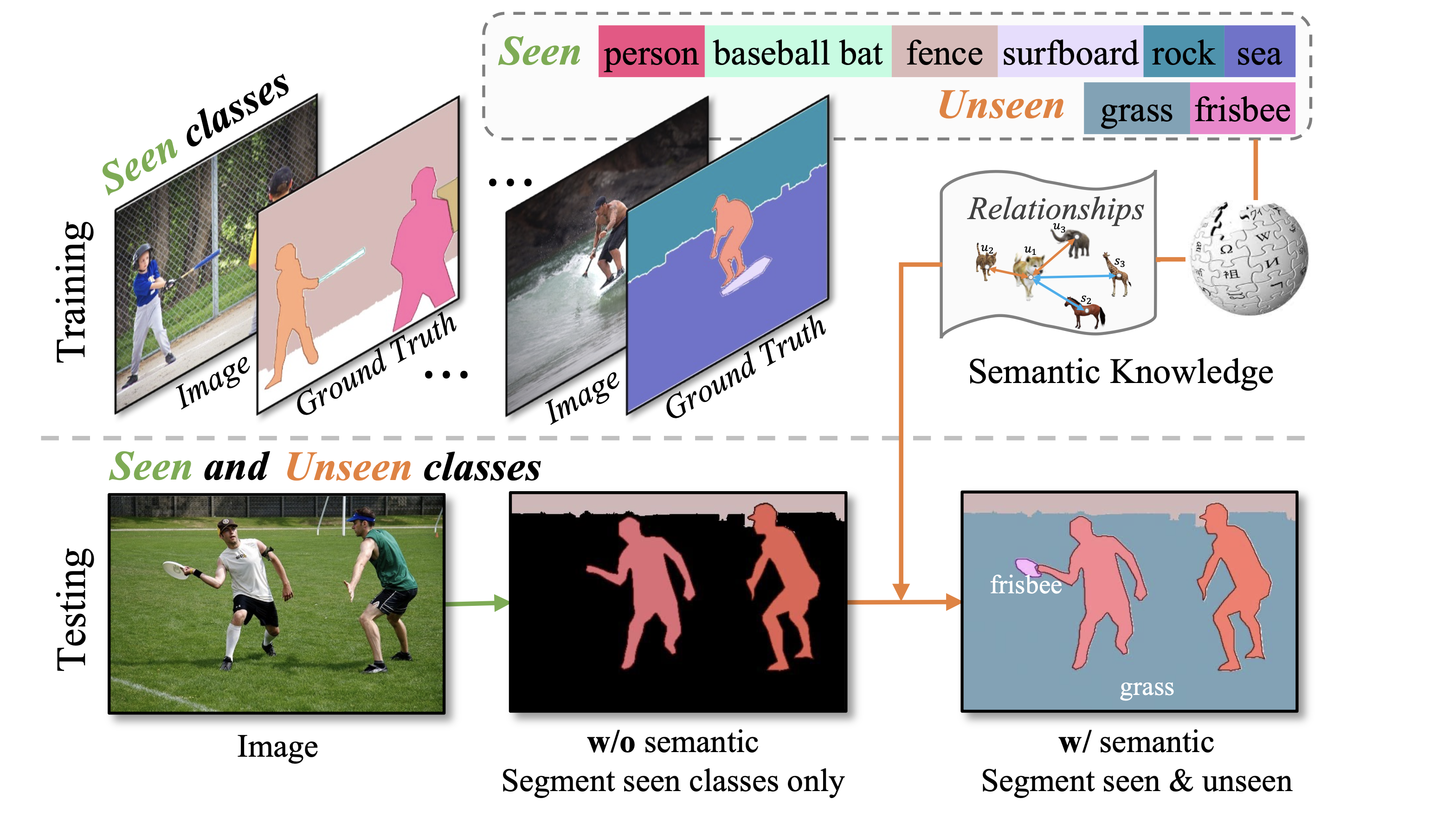
Zero-Shot Panoptic Segmentaiton (ZSP) Task: Because of the high similarities between semantic segmentation and panoptic segmentation, we develop the ZSP datasets by following the previous ZSS works. In order to avoid any information leakage, SPNet selects 15 classes in COCO stuff that do not appear in ImageNet as unseen classes. In COCO panoptic dataset, we find 14 classes overlapped with the 15 ones selected by SPNet and set them as unseen classes, i.e.,
{cow, giraffe, suitcase, frisbee, skateboard, carrot, scissors, cardboard, sky-other-merged, grass-merged, playingfield, river, road, tree-merged}, while the remaining 119 classes are set as seen classes. To guarantee no information leakage in the training set, we discard the training images that contain even one pixel of any unseen classes. Thus the model is trained by samples of seen classes only with 45617 training images. We use all 5k validation images to evaluate the performance of ZSP. Panoptic and semantic segmentation tasks are evaluated on the union of thing and stuff classes while instance segmentation is only evaluated on the thing classes.
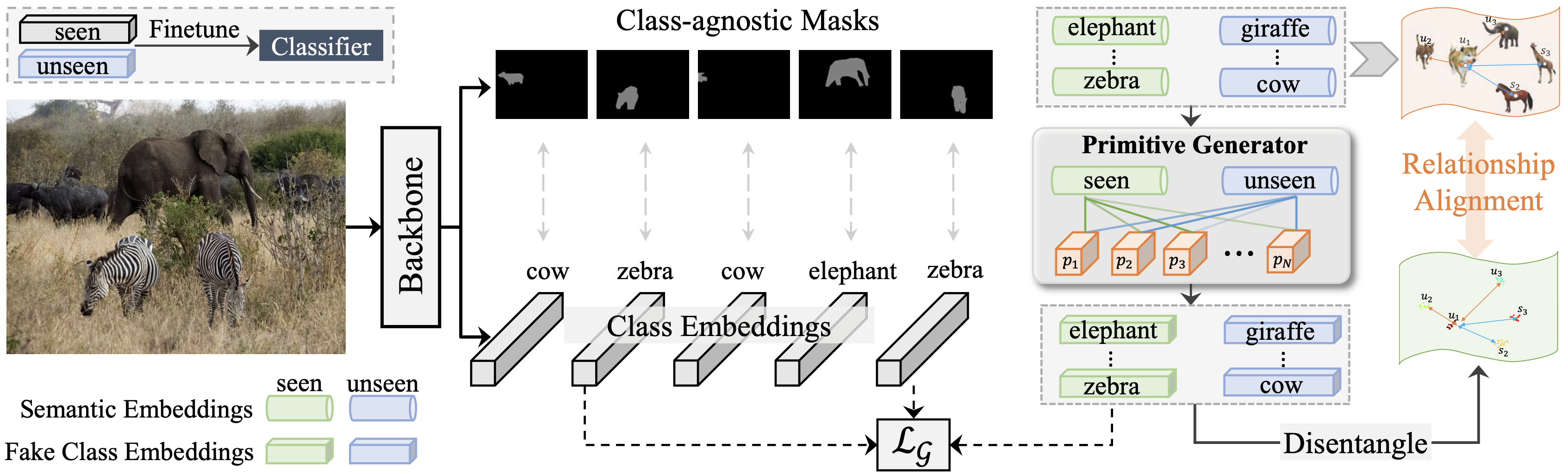
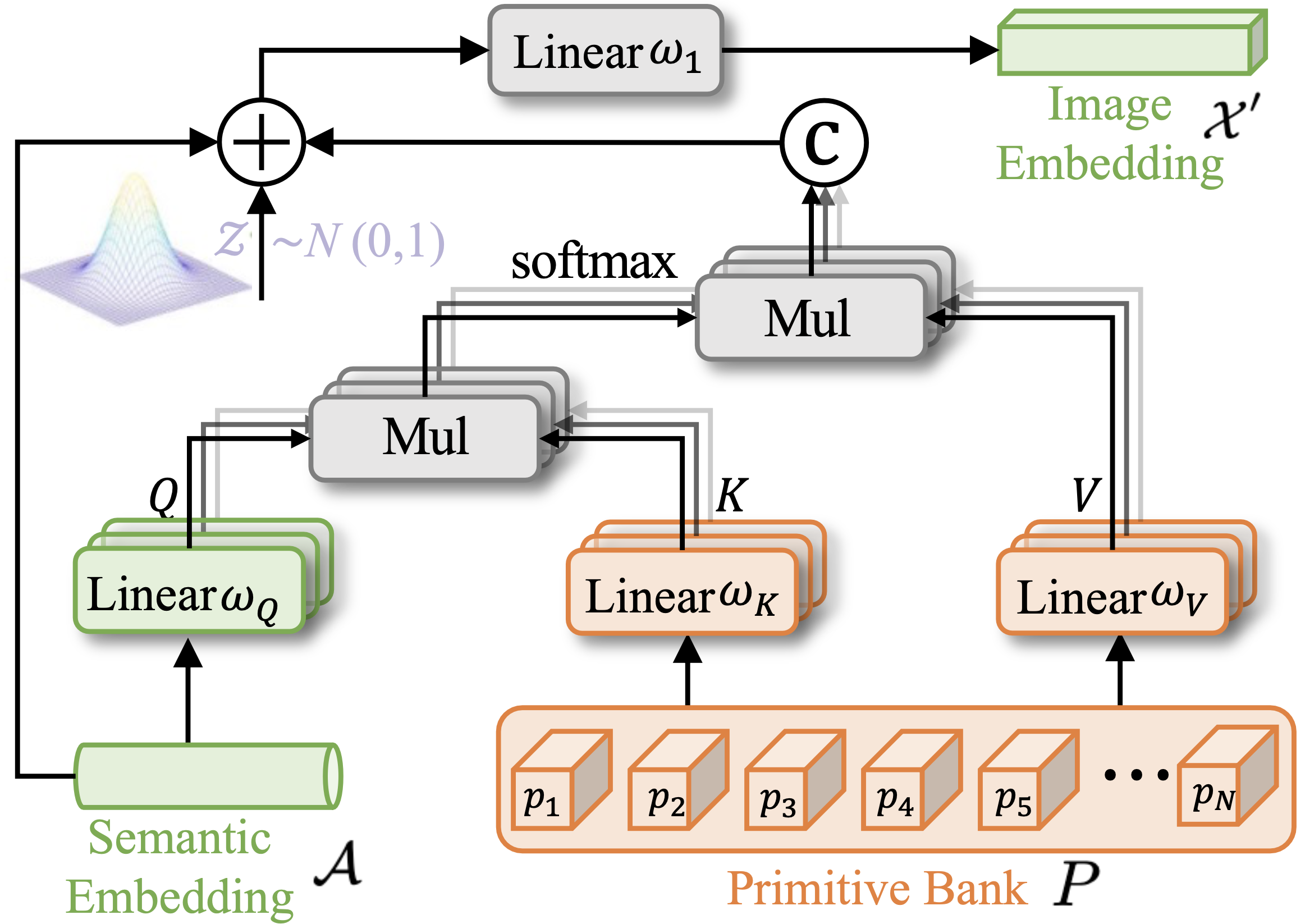
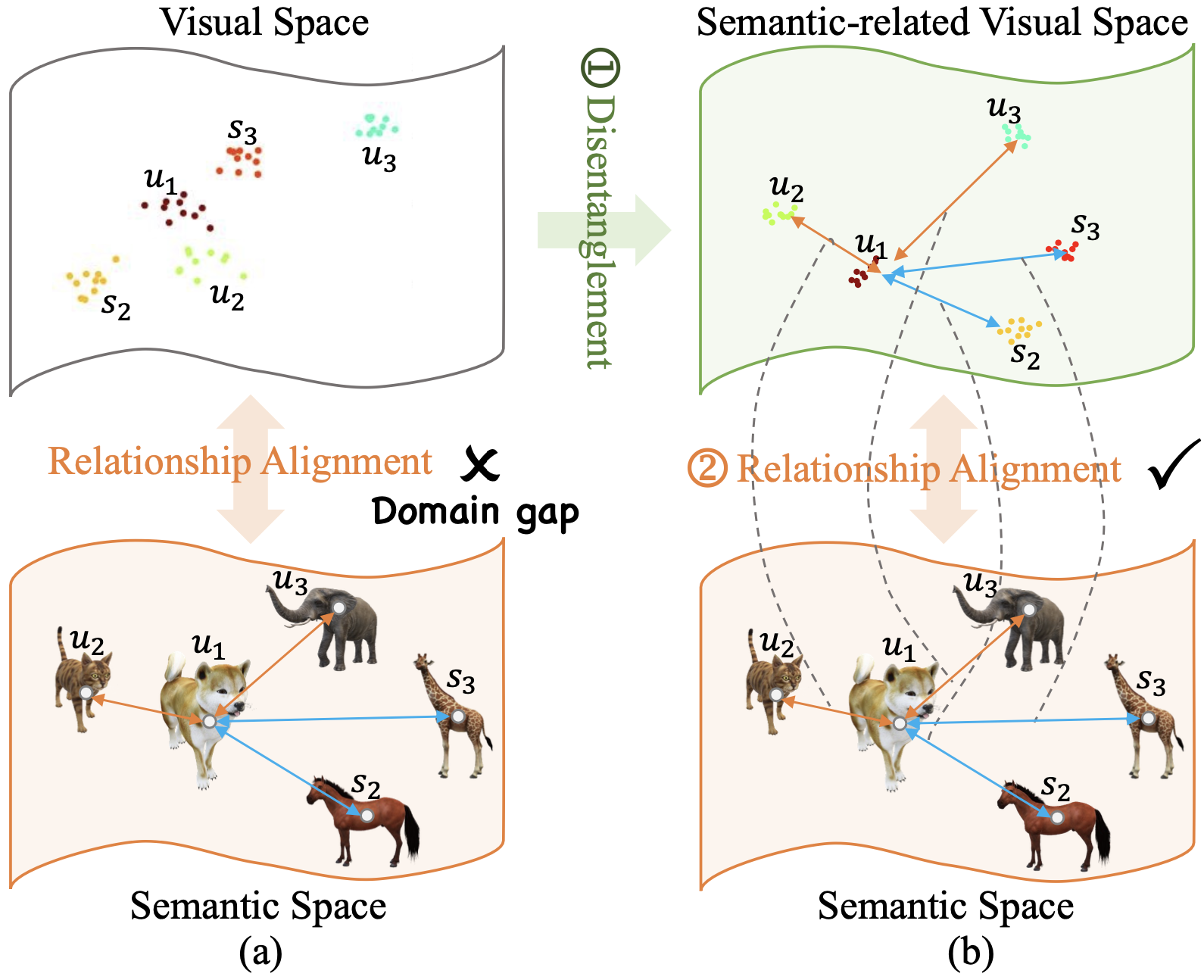
TABLE 1. Zero-shot panoptic segmentation ablation study results on MSCOCO. G, P, A, D denote GMMN generator, primitive generator,
disentanglement, and alignment, respectively.
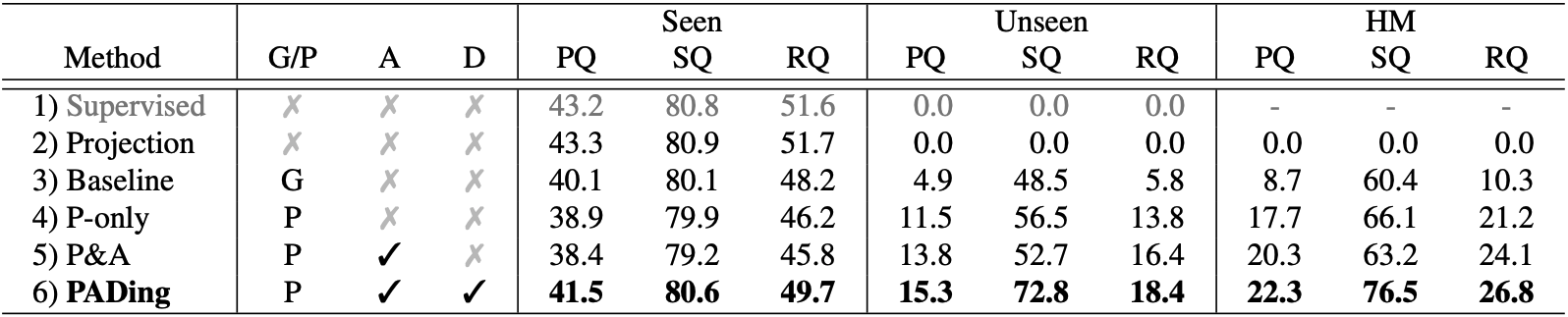 TABLE 2. Comparison with other ZSS methods on COCO-Stuff.
TABLE 2. Comparison with other ZSS methods on COCO-Stuff.
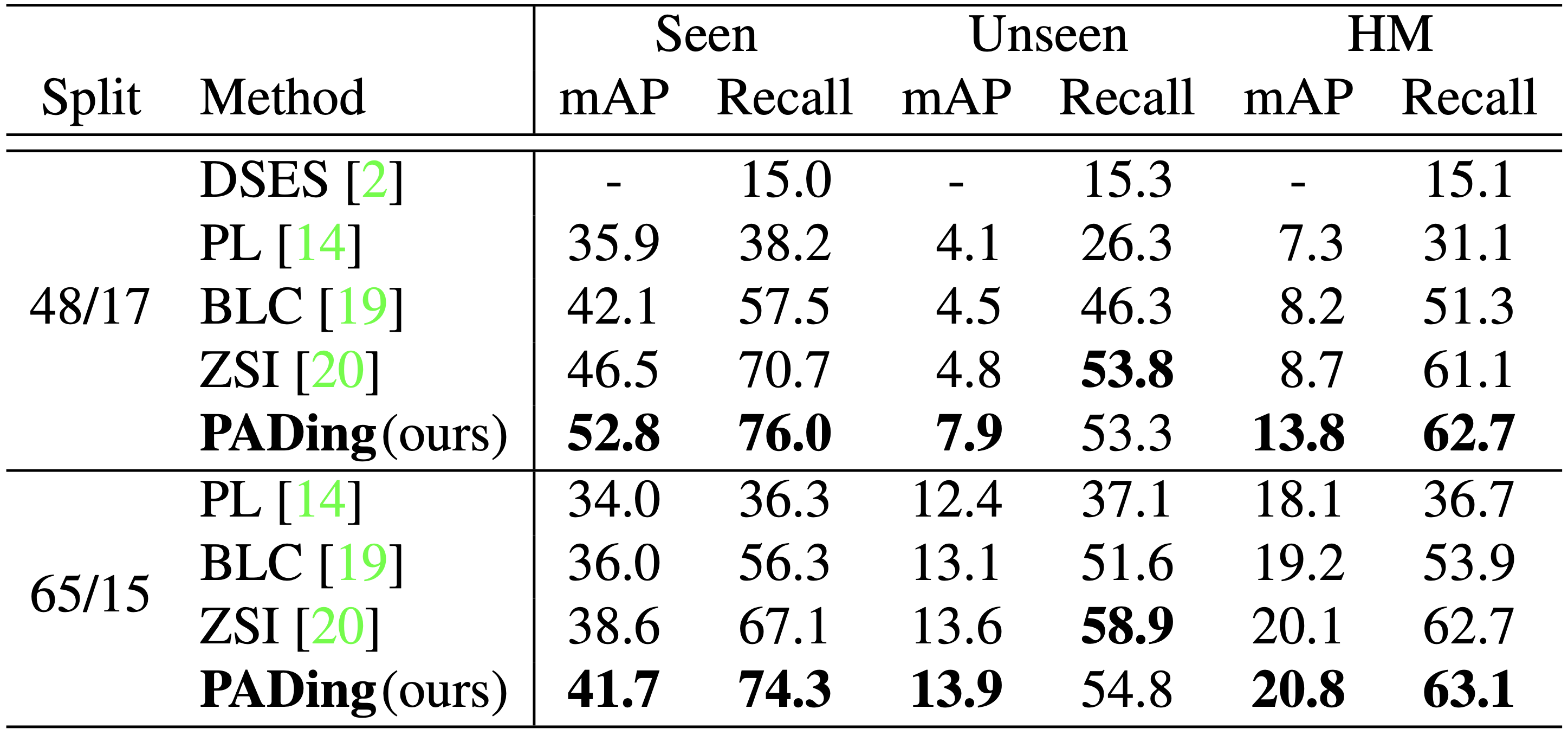
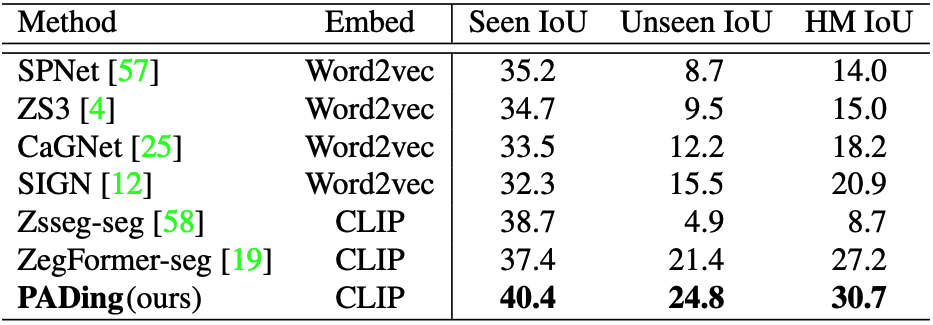 TABLE 3. Results on GZSI using word2vec embedding.
TABLE 3. Results on GZSI using word2vec embedding.
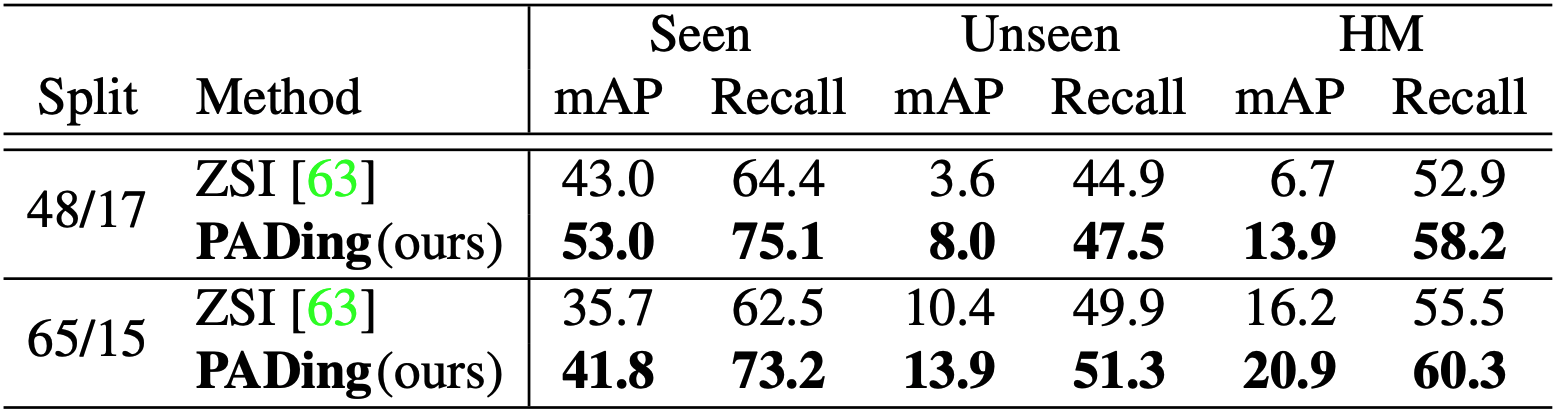 TABLE 4. Results on GZSD using word2vec embedding.
TABLE 4. Results on GZSD using word2vec embedding.