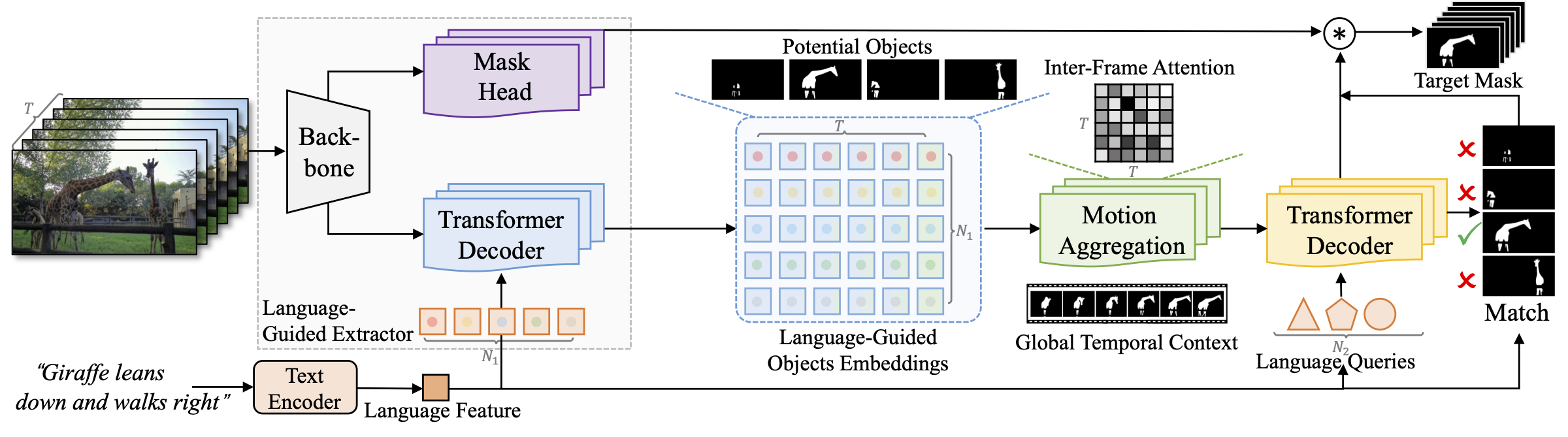
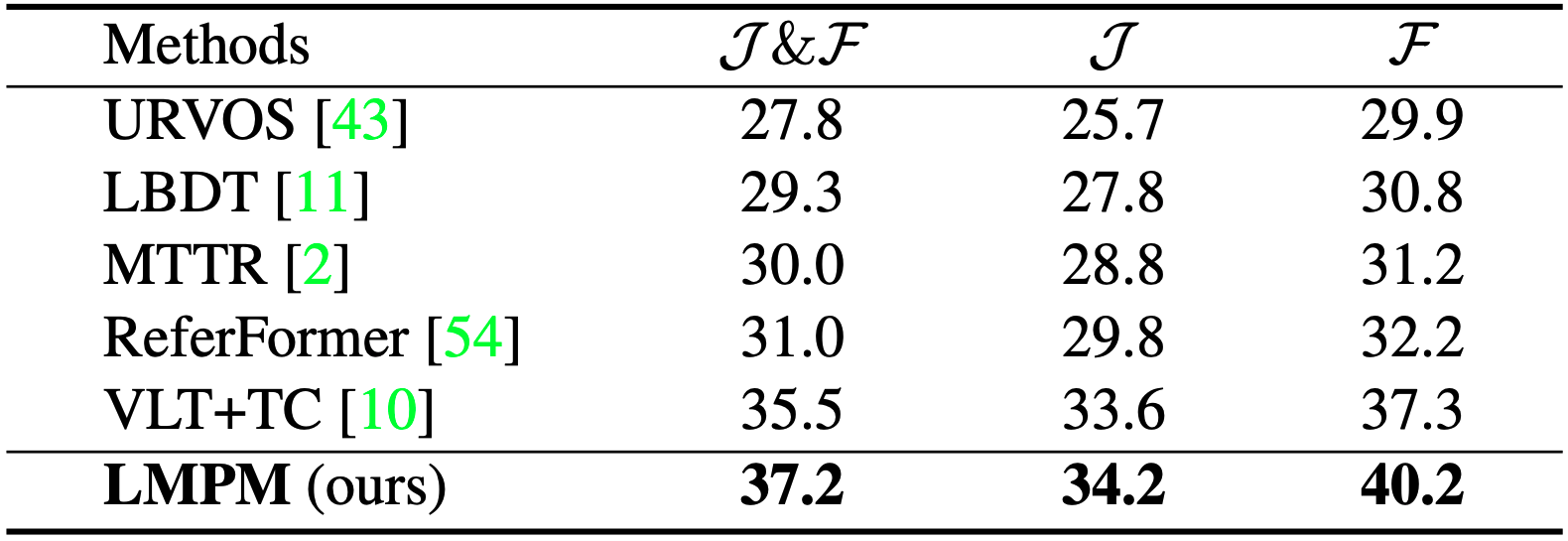
Figure 1. Examples of video clips from Motion expressions Video Segmentation (MeViS) are provided to illustrate the dataset's nature and complexity. The selected target objects are masked in orange ▇. The expressions in MeViS primarily focus on motion attributes and the referred target object cannot be identified by examining a single frame solely. For instance, the first example features three parrots with similar appearances, and the target object is identified as "The bird flying away". This object can only be recognized by capturing its motion throughout the video.