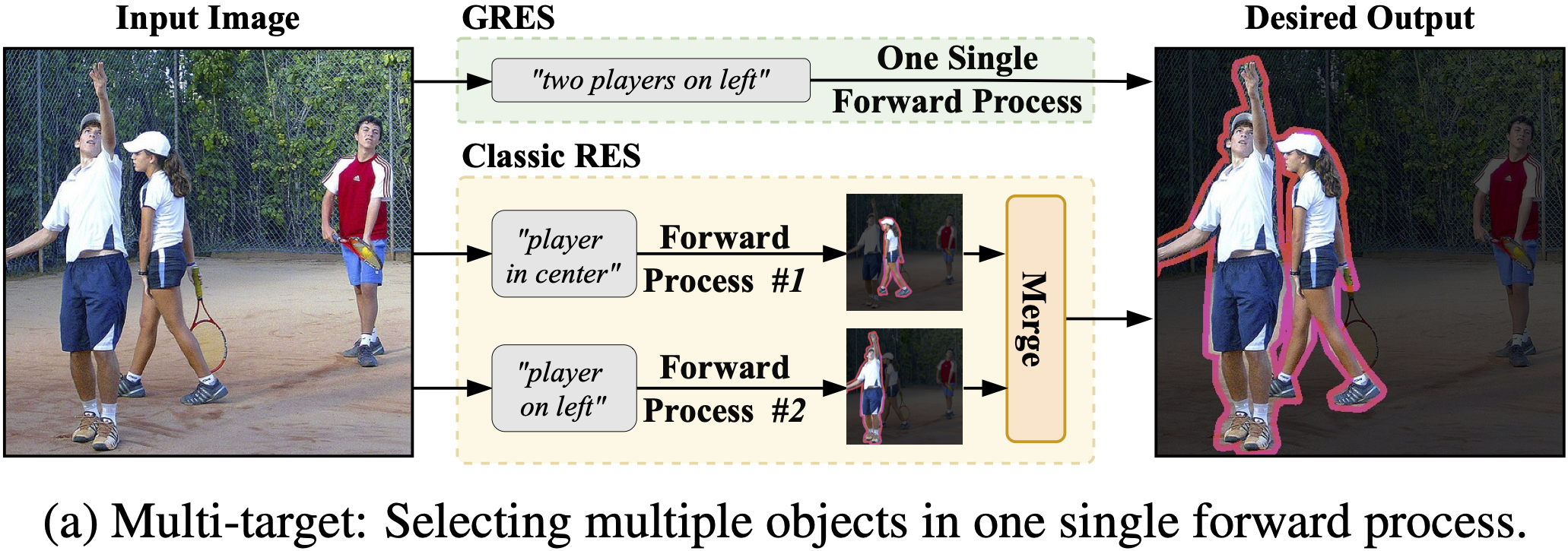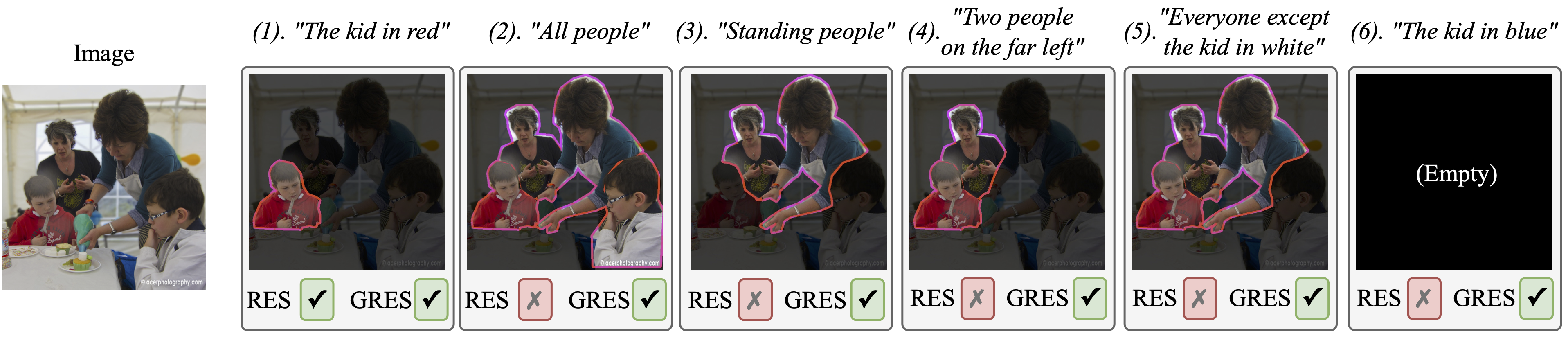
Figure 1. Classic Referring Expression Segmentation (RES) only supports expressions that indicate a single target object, e.g, (1). Compared with classic RES, the proposed Generalized Referring Expression Segmentation (GRES) supports expressions indicating an arbitrary number of target objects, for example, multi-target expressions like (2)-(5), and no-target expressions like (6). To support the GRES task, we construct the first large-scale GRES/GREC dataset called gRefCOCO.
News
- [03, 2024] Call for Papers: CVPR 2024 PVUW Workshop.
- [02, 2024] MeViS challenge and MOSE challenge will be held in conjunction with CVPR 2024 PVUW Workshop.
- [08, 2023] Generalized Referring Comprehension (GREC) is ready, please see the technical report and code.
- [08, 2023] MeViS Dataset is released, which supports expressions referring to multiple object(s) in the video.
- [08, 2023] We have updated and reorganized the dataset file. Please download the latest version for train/val/testA/testB!
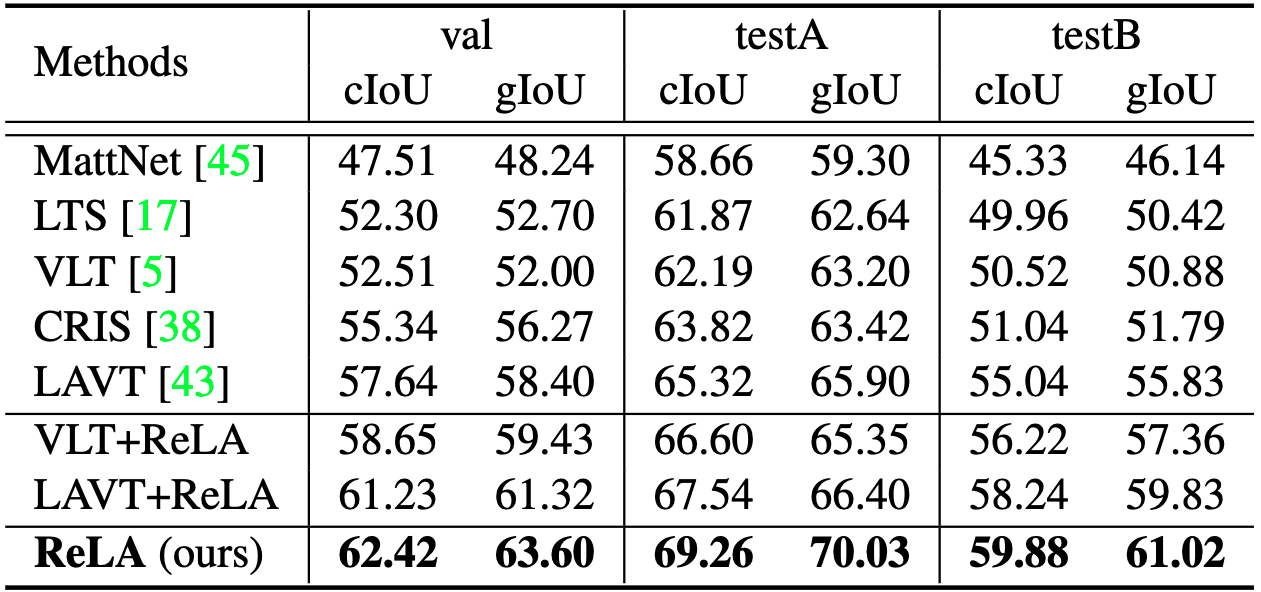
- [06, 2023] gRefCOCO Dataset and GRES method code are released.
- [03, 2023] GRES was selected as a highlight at CVPR 2023, acceptance rate 2.57%.
- [02, 2023] GRES accepted to CVPR 2023.